


Сегодня продолжаем разбирать эффективные сортировки. И на очереди у нас пирамидальная сортировка, или heap sort. В этой статье мы рассмотрим классический алгоритм сортировки кучей.
Этот алгоритм использует такую структуру данных, которая и называется куча. Куча представляет собой бинарное дерево, для которого выполняется условие, что каждый лист дерева, т. е. узел без потомков, имеет глубину d или d-1, где d — это глубина дерева.
На примере такой кучи мы и рассмотрим алгоритм. Основной же принцип этого алгоритма основан на построении и изменении бинарного дерева таким образом, чтобы в его корне всегда находилось максимальное значение.
Итак, начнём. Будем следить за алгоритмом шаг за шагом.
Шаг 1
Для начала разберёмся, каким образом получить бинарное дерево из обычного несортированного массива. Здесь всё достаточно просто: начиная с нулевого элемента последовательно заполняем уровни дерева слева направо, как показано на рисунке ниже. Получается, что корень дерева — это нулевой элемент массива, его потомки — это первый и второй элемент и, соответственно, у левой ветки потомки – это 3 и 4 элемент, а у правого – 5 и 6 и так далее.
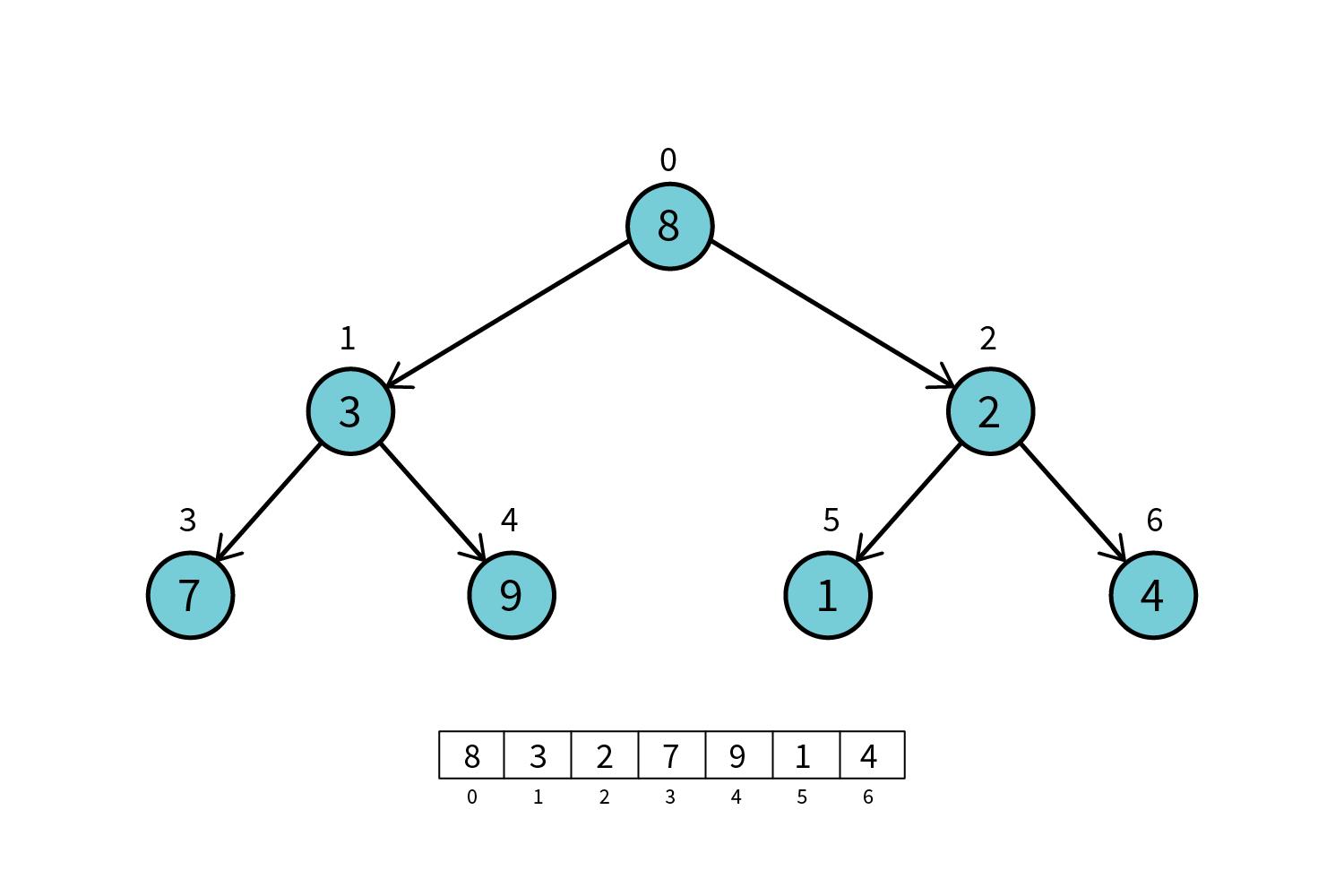
Шаг 2
Далее нам нужно преобразовать это дерево таким образом, чтобы в корне дерева находился максимальный элемент, а значение в каждом узле было больше, чем значения в его потомках. Для этого мы смотрим на предпоследний уровень дерева, и для каждого узла проверяем, выполняется условие: каждый потомок должен быть меньше своего родителя. Если нет, то находим максимальный элемент среди потомков и меняем его местом с родителем. Так проходимся по каждому уровню дерева снизу вверх и в результате мы получаем сортирующее дерево, в корне которого находится максимальное число. Преобразованное дерево будет выглядеть вот так:
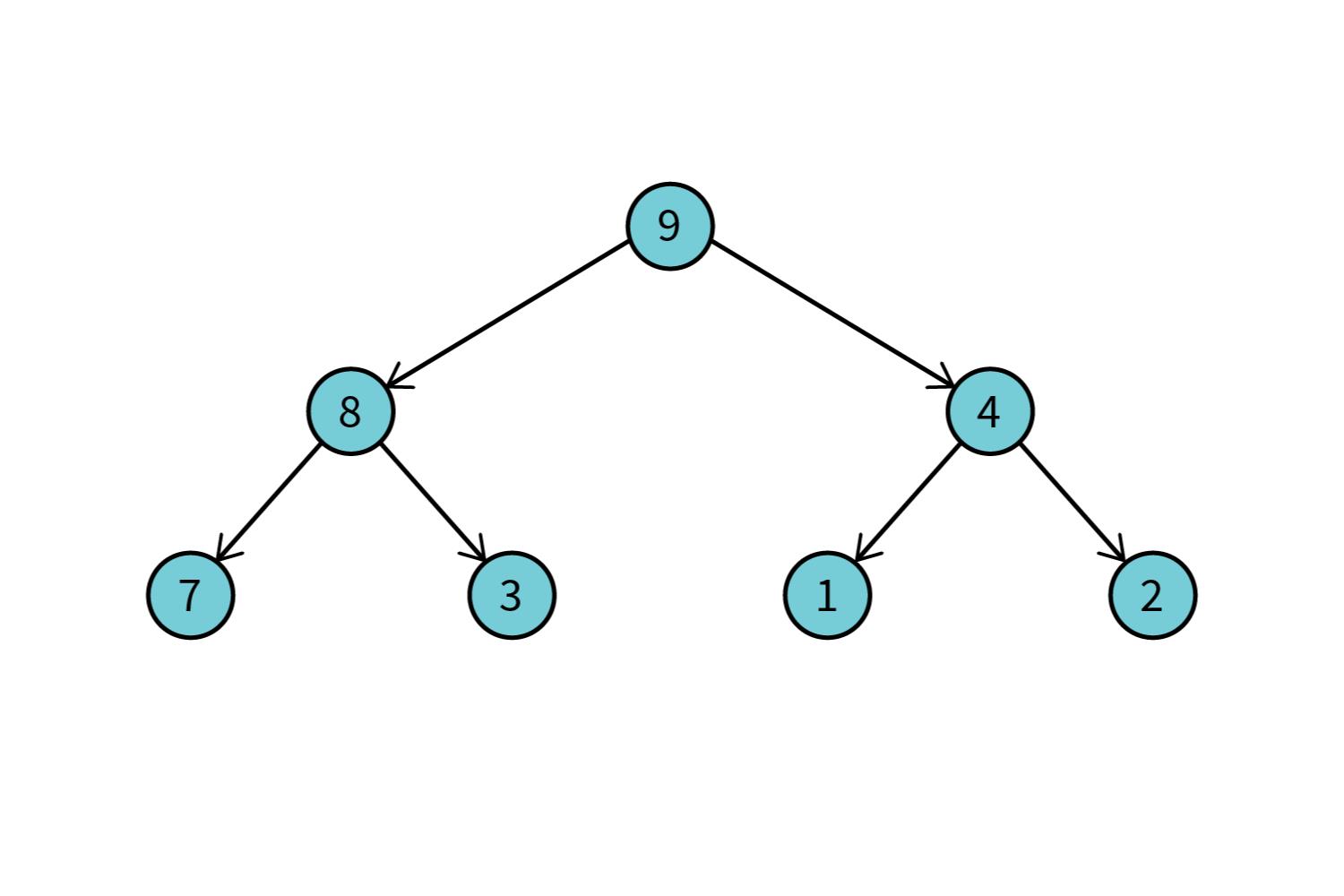
Может возникнуть вопрос, куда пропал массив? Хороший вопрос. Массив — это и есть дерево. Все перестановки, которые мы якобы делаем в дереве, — это перестановки элементов в массиве. Соответствие индексов массива и узлов было показано на первом рисунке. По сути, мы поменяли местами 1 <—> 4 элемент массива и 2 <—> 6.
Массив на этом шаге выглядит [9, 8, 4, 7, 3, 1, 2].
Шаг 3
Теперь мы поменяем местами нулевой и последний элемент массива и «отрежем» ветку с максимальным элементом.
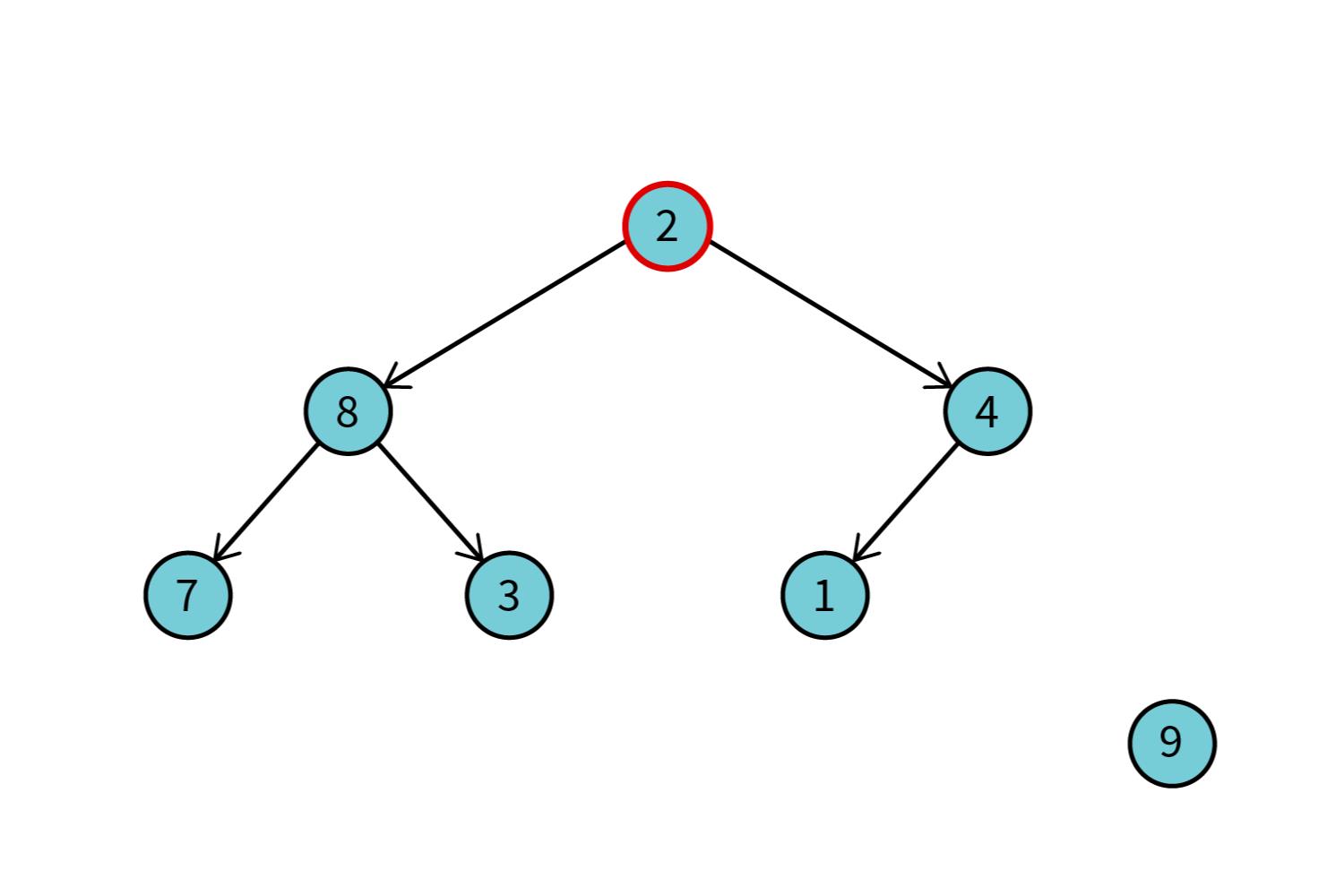
Массив теперь выглядит так: [2, 8, 4, 7, 3, 1, 9].
Шаг 4
Всё что нужно делать дальше — это похожим образом приводить дерево к такому виду, чтобы выполнялось обозначенное выше условие: каждый потомок должен быть меньше своего родителя. Действия похожие, только теперь идём сверху вниз и выполняем перестановки там, где условие нарушается. На второй итерации дерево будет выглядеть вот так:
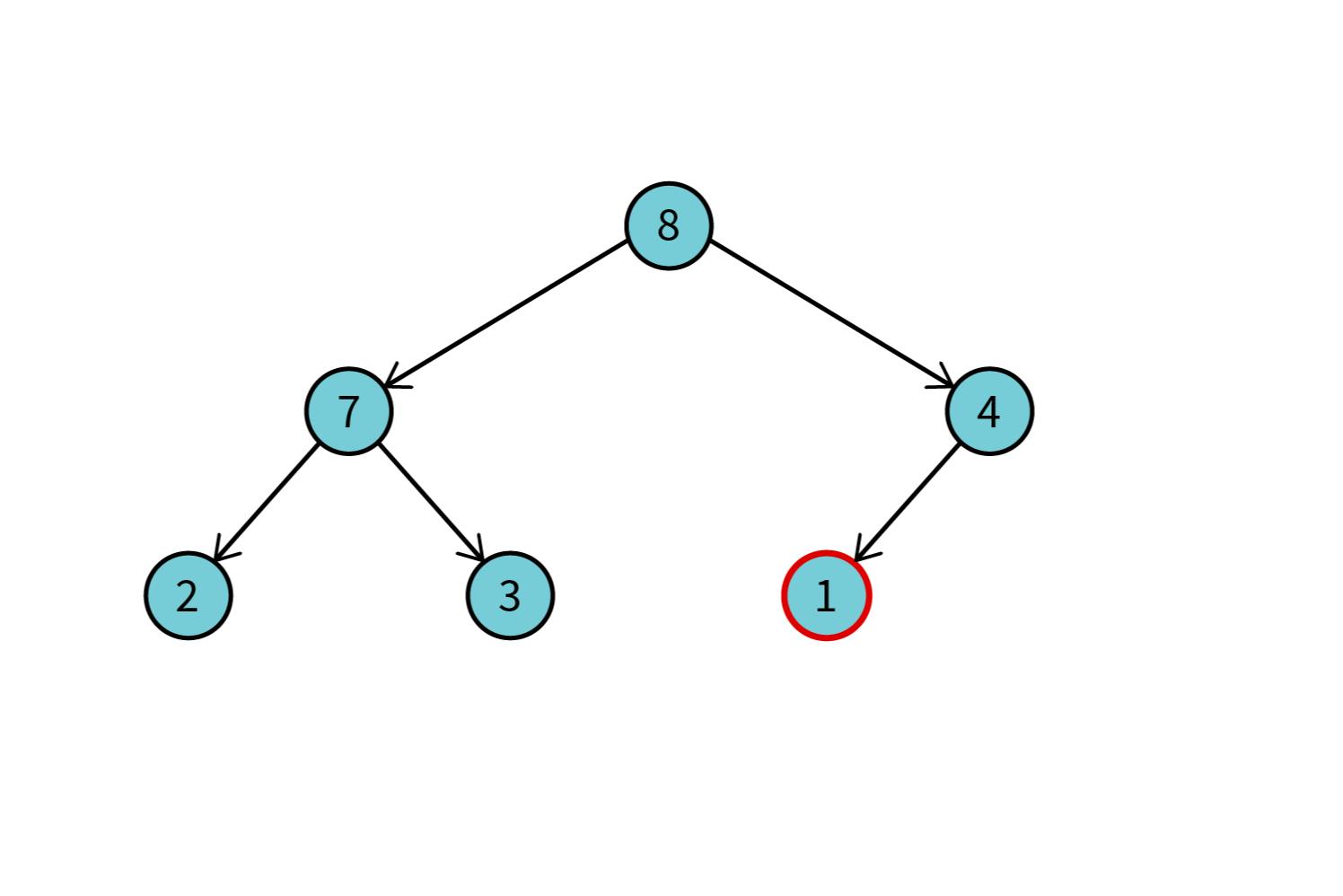
Опять у нас максимальный элемент в корне, и мы меняем его местами с предпоследним элементом массива, т. к. последний элемент и так максимальный среди всех. «Отрезаем» от дерева ветку с максимальным элементом. Массив будет выглядеть вот так: [1, 7, 4, 2, 3, 8, 9].
Таким образом, в конце массива у нас складываются уже отсортированные элементы. Итерации выполняются до тех пор, пока массив не будет полностью отсортирован, и все листья с дерева не будут срезаны.
А теперь главный вопрос: для чего же это всё затевалось? Пирамидальный алгоритм обладает отличной вычислительной сложностью и не требует дополнительной памяти. Доказанная оценка сложности в худшем случае O(n log n), что очень хорошо. При этом требуется всего O(1) памяти (по сути, буфер для выполнения перестановок). Однако в некоторых реализациях можно обойтись и без него.
Но в каждой бочке мёда есть ложка дёгтя.
- Эта сортировка неустойчива. Об этом нужно помнить, если порядок одинаковых элементов в массиве важен.
- На почти отсортированных массивах этот алгоритм будет работать так же долго, как и на случайных. Алгоритм не распараллеливается и может быть реализован только на структурах, аналогичных массиву, где есть прямой доступ к элементам по индексу. На связных списках такой алгоритм не реализовать.
- Алгоритм будет более эффективным на больших объёмах данных. Если данных немного — сортировка Шелла его обгонит.
Всегда нужно помнить, что нет идеального алгоритма сортировки, есть подходящий. А чтобы знать, из чего выбирать, в ближайшем будущем мы рассмотрим ещё несколько эффективных алгоритмов сортировки.
Ещё больше сортировок вы найдёте здесь:
_05460750.png)




